
When you’re first learning about how search engine bots work, a crawl budget may seem like a foreign concept—and often gets overlooked. However, while not the easiest search engine optimization (SEO) element, it is less complicated than it may seem.
Understanding what crawl budget is and how to optimize for it can have a significant impact on your search engine rankings and overall website visibility. This process will help your site achieve its highest potential for ranking in Google’s search results. In this blog post, we will discuss what a crawl budget is and provide tips on how to optimize it effectively. Keep reading!
What Is Crawl Budget?
If you’re wondering about the crawl budget, the concept is pretty straightforward. The crawl budget is the number of URLs from one website that search engine bots can index within one indexing session. Google bots systematically go through a website to determine what the pages are about.
The crawlers process, categorize, and organize data from a website page by page to create a cache of URLs and their content. This way, Google can determine which search results should appear on the search engine results page (SERP) in response to a search query and in what order.
The “budget” of a crawl session differs from website to website based on each site’s size, traffic metrics, and page load speed. As the crawlers have limited resources, website owners need to ensure that these are allocated efficiently to crawl and index the most important pages.
If you’ve gotten this far and the SEO terms are unfamiliar to you, use our SEO glossary to become more acquainted with the definitions.

What Factors Affect a Website’s Crawl Budget?

Google doesn’t devote the same amount of time or number of crawls to every website on the internet. Web crawlers also determine which pages they crawl and how often based on several factors. They determine how often and for how long each site should be crawled based on:
- Popularity: The more a site or page is visited, the more often it should be analyzed for updates. Furthermore, more popular pages tend to accumulate inbound links more rapidly.
- Frequency of updates: Websites that regularly publish fresh, high-quality content are typically crawled more frequently by search engine bots.
- Size: Large websites and pages with more data-intense elements on the architecture take longer to crawl.
- Health/Issues: When a web crawler reaches a dead-end through internal links, it takes time for it to find a new starting point–or it abandons the crawl. 404 errors, URL redirection, and slow loading times slow down and stymie web crawlers.
How Does Your Crawl Budget Affect SEO?
The web crawler indexing process is what makes search possible. If your content cannot be found and then indexed by Google’s bots, your web pages–and website as a whole—will not be discoverable by searchers. This would lead to your site missing out on a lot of search traffic.
During a crawl, Google allots a set amount of time for a bot to process a website. Because of this limitation, the bot likely will not crawl an entire site during one session. Instead, it will work its way through all the site’s pages based on the robots.txt file and other factors (such as a page’s popularity).
During the crawl session, a Googlebot will use a systematic approach to understanding the content of each page it processes.
This includes indexing specific attributes, such as:
- Meta tags and using Natural Language Processing (NLP) to determine their meaning.
- Links and anchor text.
- Rich media files for image searches and video searches.
- Schema markup.
- HTML markup.
The web crawler will also check to determine if the page’s content is a duplicate of a canonical. If so, Google will move the URL to a low-priority crawl so it doesn’t waste time crawling the page as often.
What Are Crawl Rate and Crawl Demand?
As you already learned, Google’s web crawlers assign a certain amount of time to every crawl they perform. As a website owner, you have no control over this. However, you can change how quickly they crawl individual pages on your site. This number is called your crawl rate.
Crawl demand is how often Google crawls your site. This frequency is based on the demand of your site by internet users and how often your site’s content needs to be updated on search. You can discover how often Google crawls your site using a log file analysis (see #2 below).
How Can I Determine My Site’s Crawl Budget?

Because Google limits the number of times they crawl your site and for how long, you want to be aware of what your crawl budget is. However, Google doesn’t provide site owners with this data–especially if your budget is so narrow that new content won’t hit the SERPs promptly.
This can be disastrous for search engine indexing of important content and new pages—like product pages, which could make you money. To understand if your site is facing crawl budget limitations (or to confirm that your site is A-OK), you will want to:
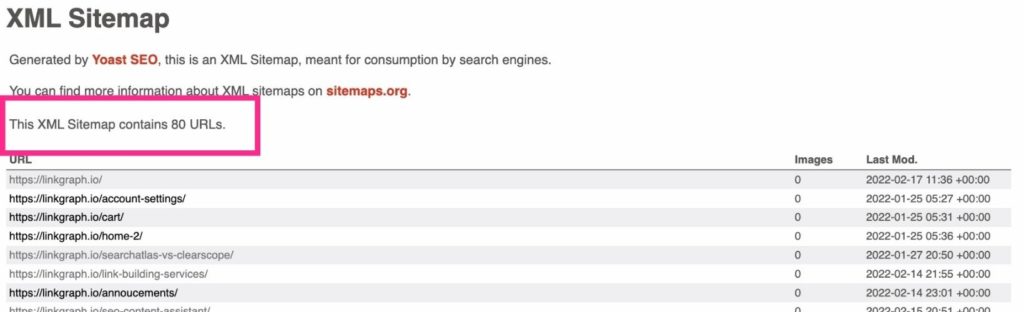
- Get an inventory of how many URLs are on your site. If you use Yoast, your total will be listed at the top of your sitemap URL.
- Once you have this number, use the “Settings” > “Crawl stats” section of Google Search Console to determine how many pages Google crawls on your site daily.
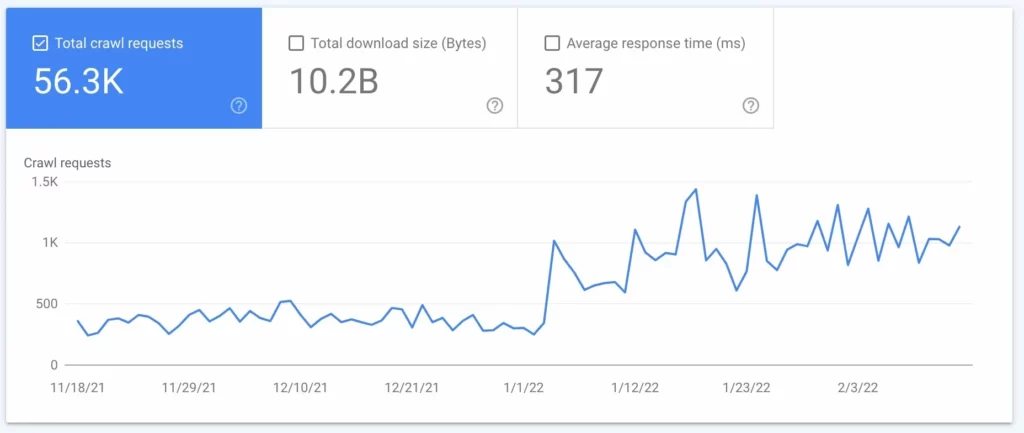
- Divide the number of pages on your sitemap by the average number of pages crawled per day.
- If the result is below 10, your crawl budget should be fine. However, if your number was lower than 10, you could benefit from crawl budget optimization.
How Can You Optimize Your Crawl Budget?
When your site becomes too big for its crawl budget, you will need to dive into crawl budget optimization. Because you cannot tell Google to crawl your site more often or for a longer period of time, you must focus on what you can control.
Crawl budget optimization requires a multi-faceted approach and an understanding of Google’s best practices. Where should you start when it comes to making the most of your crawl rate? This comprehensive list is written in hierarchical order, so begin at the top.
1. Consider Increasing Your Site’s Crawl Rate Limit
Google sends requests simultaneously to multiple pages on your site. However, it tries to be courteous and not bog down your web server, resulting in slower load time for your site visitors. If you notice your site lagging out of nowhere, this may be the problem.
To combat the effects on your users’ experience, Google allows you to reduce your crawl rate. Doing so will limit how many pages it can index simultaneously.
Interestingly enough, though, Google also allows you to raise your crawl rate limit. The effect is that they can pull more pages at once, resulting in more URLs being crawled. Although all reports suggest Google is slow to respond to a crawl rate limit increase, it doesn’t guarantee that Google will crawl more sites simultaneously.
To increase your crawl rate limit:
- In Search Console, go to “Settings.”
- From there, you can view if your crawl rate is optimal or otherwise.
- Then, you can increase the limit to a more rapid crawl rate for 90 days.
2. Perform a Log File Analysis

A log file analysis is a report from the server that reflects every request sent to it. This report will tell you exactly what the Googlebot does on your site. While this process is often performed by technical SEOs, you can talk to your server administrator to obtain one.
Using your Log File Analysis or server log file, you will learn:
- How frequently Google crawls your site
- What pages get crawled the most
- Which pages have an unresponsive or missing server code
Once you have this information, you can use it to perform #3 through #7.
3. Keep Your XML Sitemap and Robots.txt Updated
If your Log File shows that Google is spending too much time crawling pages you do not want appearing in the SERP, you can request that the crawlers skip these pages. This frees up some of your crawl budget for more important pages.
Your sitemap (which you can obtain from Google Search Console or Search Atlas) gives Googlebot a list of all the pages on your site that you want Google to index so they can appear in search results.
Keeping your sitemap updated with all the web pages you want search engines to find and omitting those that you do not want them to find can maximize how web crawlers spend their time on your site.
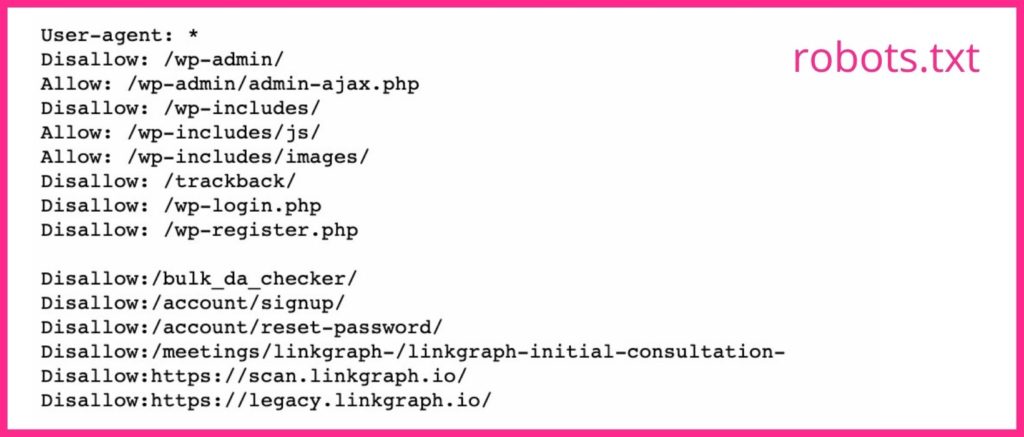
Your robots.txt file tells search engine crawlers which pages you want and do not want them to crawl. If you have pages that don’t make good landing pages or pages that are gated, you should use the noindex tag for their URLs in your robots.txt file. Google bots will likely skip any webpage with the no index tag.
4. Reduce Redirects & Redirect Chains
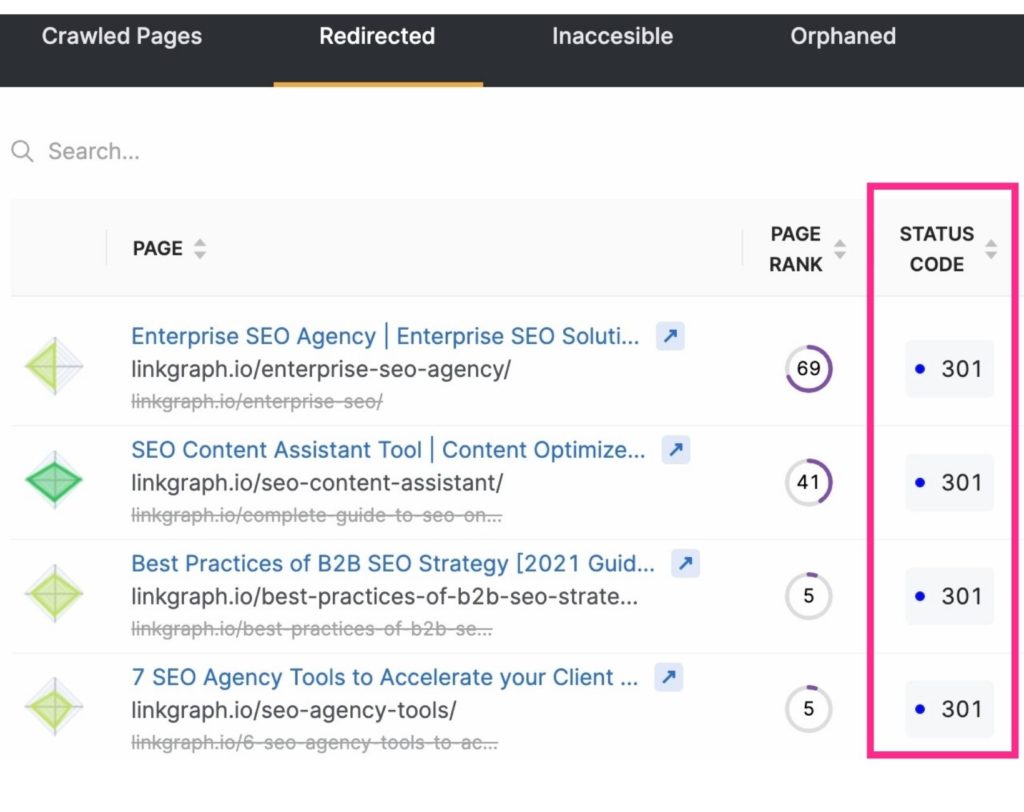
In addition to freeing up the crawl budget by excluding unnecessary pages from search engine crawls you can maximize crawls by reducing or eliminating redirects. These will be any URLs that result in a 301 status code.
Redirected URLs take longer for bots to retrieve since the server has to respond with the redirect and then retrieve the new page. While one redirect takes just a few milliseconds, they can add up.
This can make crawling your site take longer overall. This amount of time is multiplied when a Googlebot runs into a chain of URL redirects. To reduce redirects and redirect chains, be mindful of your content creation strategy and carefully select the text for your slugs.
5. Fix Broken Links
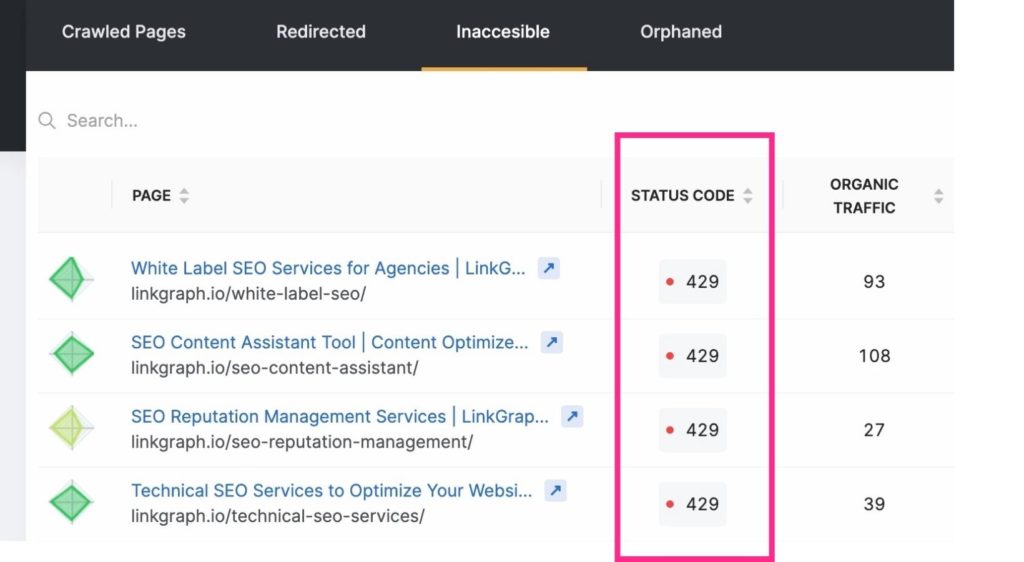
The algorithm often explores a site by navigating via your internal link building structure. As it works its way through your pages, it will note if a link leads to a non-existent page (this is often referred to as a soft 404 error). It will then move on, not wanting to waste time indexing said page.
The links to these pages need to be updated to send the user or the Googlebot to a real page. Or (while it’s hard to believe), the Googlebot may have misidentified a page as a 429 or a 404 error when the page exists.
When this happens, check that the URL doesn’t have any typos, then submit a crawl request for that URL through your Google Search Console account. To stay current with these crawl errors, you can use your Google Search Console account’s Index > Coverage report. Or use Search Atlas’s Site Audit tool to find your site error report and pass it along to your web developer.
Note: New URLs may not appear in your Log File Analysis right away. Give Google some time to find them before requesting a crawl.
6. Work on Improving Page Load Speeds
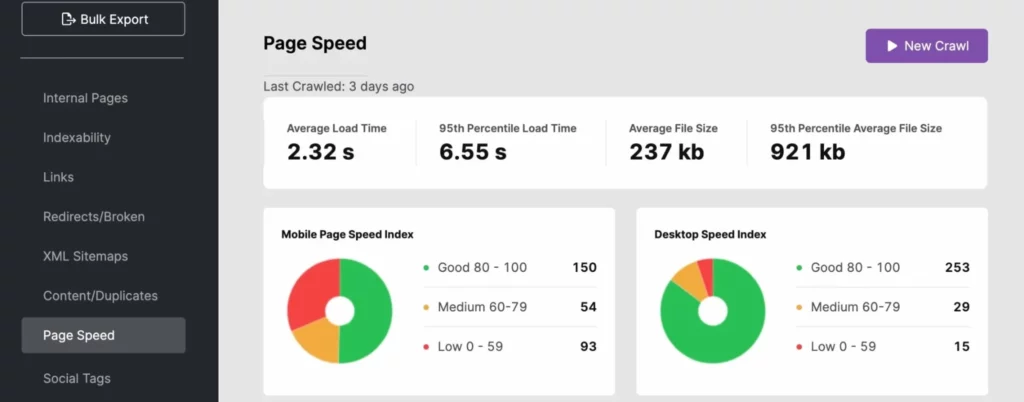
Search engine bots can move through a site at a rapid pace. However, if your site’s speed isn’t up to par, it can take a major toll on your crawl budget. Use your Log File Analysis, Search Atlas, or PageSpeedInsights to determine if your site’s load time is negatively affecting your search visibility.
To improve the response time, use dynamic URLs and follow Google’s Core Web Vitals best practices. This can include image optimization for media above the fold.
If the site speed issue is on the server side, you may want to invest in other server resources, such as:
- A dedicated server (especially for large sites).
- Upgrading to newer server hardware.
- Increasing RAM.
These improvements will also boost your user experience, which can help your site perform better in Google search. Site speed is a signal for PageRank.
7. Don’t Forget to Use Canonical Tags
Google frowns upon duplicate content, at least when you don’t acknowledge that the content has a source page. Why? Googlebot crawls every page unless inevitably or told to do otherwise.
But when it comes across a duplicate page or a copy of something it’s familiar with (on your page or off-site), it will stop crawling that page. While this saves time, you should save the crawler even more time by using a canonical tag that identifies the canonical URL.

Canonicals tell the Googlebot not to bother using your crawl time period to index that content. This gives the crawler more time to examine your other pages.
8. Focus on Your Internal Linking Structure
Having a well-structured linking practice within your site can increase the efficiency of a Google crawl. Internal links tell Google which pages on your site are the most important, helping the crawlers find pages more easily.
The best linking structures connect users and bots to content throughout your website. Always use relevant anchor text and place your links naturally throughout your content.

For e-commerce sites, Google has best practices for faceted navigation options to maximize crawls. Faceted navigation allows site users to filter products by attributes, making shopping a better experience. This update helps avoid canonical confusion and duplicate issues, in addition to excess URL crawls.
9. Prune Unnecessary Content

Bots can only move so fast and index so many pages each time they crawl a site. If you have a high number of pages that do not receive traffic or have outdated or low-quality content–cut them!
The pruning process on your content marketing and SEO strategy lets you cut away your site’s excess baggage that can be weighing it down. Just remember to redirect any links to these pages so you don’t wind up with crawl errors.
10. Accrue More Backlinks
Just as Googlebot arrives at your site and then begins to index pages based on internal links, it also uses external links in the indexing process. If other sites link to yours, the crawler will travel over to your site and index pages to better understand the linked content.
Additionally, backlinks give your site a bit more popularity, authority, visibility, and recency, which Google uses to determine how often your site needs to be indexed.
11. Eliminate Orphan Pages
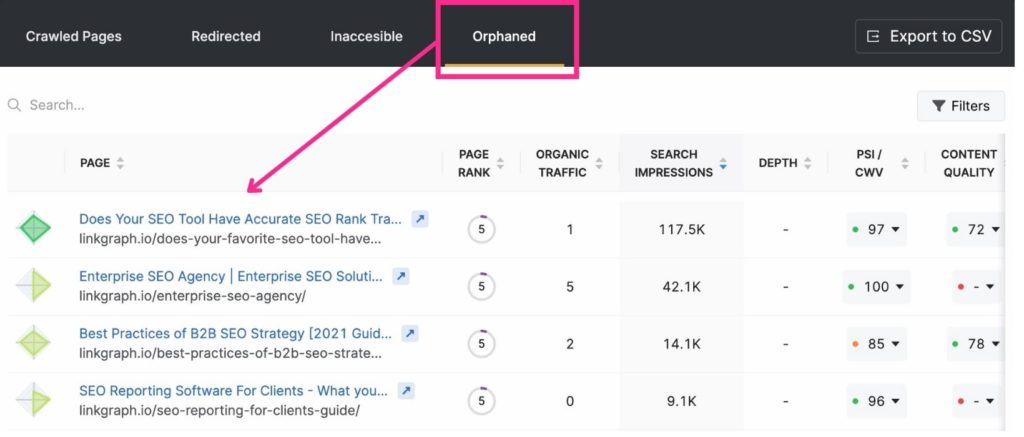
Because Google’s crawler hops from page to page through internal links, it can find pages that are linked to effortlessly. However, pages that are not linked to somewhere on your site often go unnoticed by Google. These are referred to as “orphan pages.”
When is an orphan page appropriate? If it’s a landing page that has a very specific purpose or audience. For example, if you send out an email to golfers who live in Miami with a landing page that only applies to them, you may not want to link to the page from another.
The Best Tools for Crawl Budget Optimization
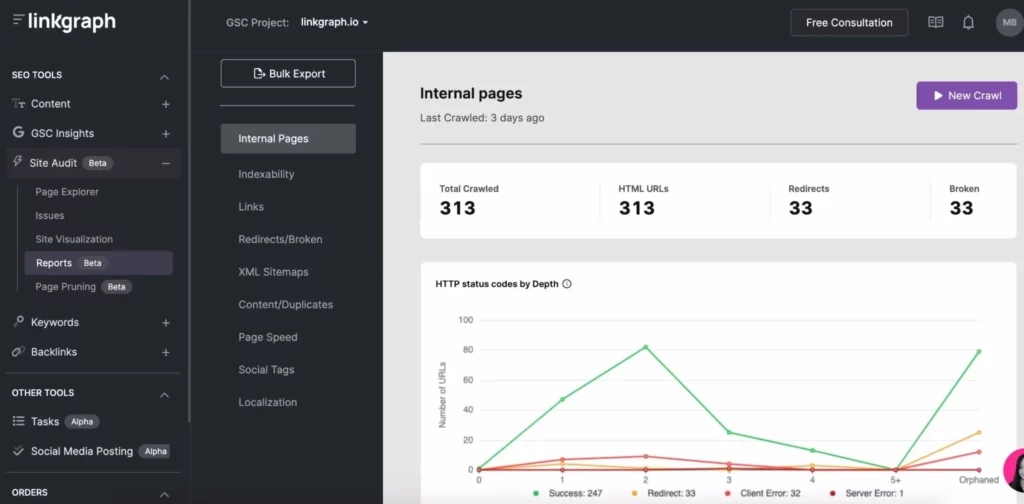
Search Console and Google Analytics can come in quite handy when it comes to optimizing your crawl budget. Search Console allows you to request a crawler to index pages and track your crawl stats. Google Analytics helps you track your internal linking journey.
Other SEO tools, such as Search Atlas, allow you to find crawl issues easily through Site Audit tools. With one report, you can see your site’s:
- Indexability crawl report.
- Index depth.
- Page speed.
- Duplicate content.
- XML sitemap.
- Links.
Optimize Your Crawl Budget & Become a Search Engine Top Performer
While you cannot control how often search engines index your site or for how long, you can optimize your site to make the most of each of your search engine crawls. Begin with your server logs and take a closer look at your crawl report on Search Console. Then, dive into fixing any crawl errors, your link structure, and page speed issues.
As you work through your GSC crawl activity, focus on the rest of your SEO strategy, including link building and adding quality content. Over time, you will find your landing pages climbing the search engine results pages.
To enhance your digital marketing efforts, book a call with our award-winning SEO experts and learn how we can help increase your traffic and revenue.
